Hadoop cluster configuration using Ansible

Ansible
No one likes repetitive tasks. With Ansible, IT admins can begin automating away the drudgery from their daily tasks. Automation frees admins up to focus on efforts that help deliver more value to the business by speeding time to application delivery, and building on a culture of success. Ultimately, Ansible gives teams the one thing they can never get enough of: time. Allowing smart people to focus on smart things.
Ansible is a simple automation language that can perfectly describe an IT application infrastructure. It’s easy-to-learn, self-documenting, and doesn’t require a grad-level computer science degree to read. Automation shouldn’t be more complex than the tasks it’s replacing.
Hadoop
The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.
About the project
🔰 11.1 Configure Hadoop and start cluster services using Ansible Playbook
🔰 11.2 Create a Article, blog or Video on how industries are solving challenges using Ansible.
🔰 11.3 Restarting HTTPD Service is not idempotence in nature and also consume more resources suggest a way to rectify this challenge in Ansible playbook
Output

Steps followed


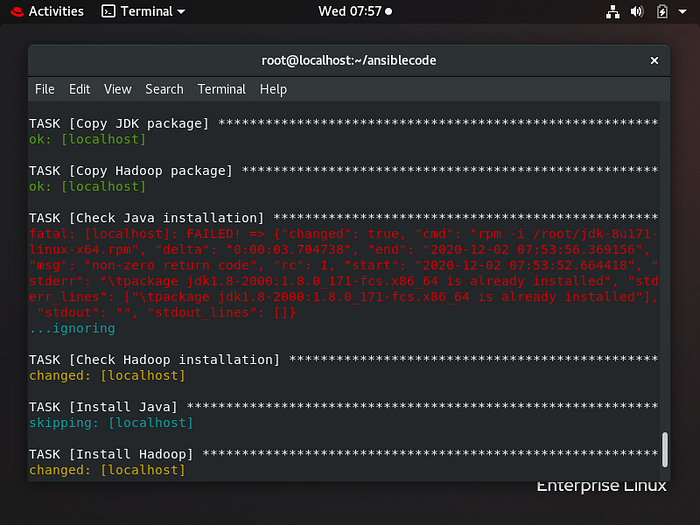

The steps for the same are written in the playbook . The code for the same can be found in github.